AI打造蒙娜丽莎系列表情包

“蒙娜丽莎”因为其神秘的微笑而闻名于世。最近在人工智能的帮助下,这张著名的脸展示出了一系列令人震惊的新表情。
在一段5月21日分享在YouTube的一段视频中,分别有三个不同片段展示了紧张不安的蒙娜丽莎动嘴唇和转头时的样子。视频中的蒙娜丽莎是由卷积神经网络创造的,卷积神经网络是一种像人脑一样处理信息的人工智能,可以用来分析和处理图像。
研究人员对该算法进行了训练,使其能够理解面部特征的一般形状及其相互之间的关系,然后研究人员将这些信息应用于静止图像上。最终,一幅单一的画面变成了一段真实的视频。
来自斯科尔科沃科技研究所和三星人工智能中心(莫斯科)的工程师叶戈尔·扎哈罗夫在这段《蒙娜丽莎》的视频中解释说:“人工智能‘学习’了三位模特的面部运动数据集,并且生成了三个截然不同的动画。虽然在这三个视频片段中人们仍然能辨认出蒙娜丽莎,但三位模特的外貌和行为的变化赋予了这些‘活生生的肖像’以鲜明的个性。”
扎哈罗夫和他的同事还根据20世纪的文化偶像,如阿尔伯特·爱因斯坦、玛丽莲·梦露和萨尔瓦多·达利的照片制作了动画。研究人员在5月20日发表在arXiv杂志网络版上的一项研究中描述了他们的发现,但是这项研究没有经过同行评审。

研究人员写道,这类视频被称为deepfakes,制作这样的原创视频并不容易。人的头部具有几何复杂性和高度的动态性,并且头部的三维模型有“数千万个参数”。
更重要的是,这项研究表明,人类的视觉系统非常善于识别三维模型人脑中的“哪怕是很小的错误”。一些看起来很像人类但并不完全属于人类的东西,会引发一种“恐怖谷效应”(uncanny valley effect),并给人们带来深深的不安感。
人工智能此前已经证明,制作令人信服的deepfakes是可能的,但是需要从多个角度拍摄目标对象。在这项新研究中,工程师们将人工智能引入了一个非常大的数据集,里面有显示人脸活动的参考视频。科学家们建立了适用于任何一张脸的面部地标,来教授“神经网络”人脸运动的一般规律。
然后,他们训练AI使用参考表达式来映射源特征的移动。研究人员称,这使得人工智能即使只有一张图片可用,也能创建deepfakes。
科学家们写道:“更多的源图像在最终动画中提供了更详细的结果。在一项用户研究中,一段用三十二张图片而不是一张图片制作的视频达到了堪称完美的真实性。”
相关推荐
-
 Android 12“App Pairs”功能:允许用户并排使用两个应用
Android 12“App Pairs”功能:允许用户并排使用两个应用
-
 NASA新火箭关键测试不幸失败 美登月计划或被迫推迟?
NASA新火箭关键测试不幸失败 美登月计划或被迫推迟?
-
 迅雷高速通道破解方法 迅雷高速通道如何破解
迅雷高速通道破解方法 迅雷高速通道如何破解
-
 ubuntu手机操作系统 手机版Ubuntu将给哪些人带来好处?
ubuntu手机操作系统 手机版Ubuntu将给哪些人带来好处?
-
 电脑开关机音乐下载 电脑开关机音乐设置教程
电脑开关机音乐下载 电脑开关机音乐设置教程
-
 去年12月中国手游发行商全球收入排名:腾讯第一
去年12月中国手游发行商全球收入排名:腾讯第一
-
 长城汽车申请新商标曝光啦!
长城汽车申请新商标曝光啦!
-
 网友晒“哈哈哈”频率 有的人居然一年哈了8.6万次
网友晒“哈哈哈”频率 有的人居然一年哈了8.6万次
-
 华硕x88s拆机教程 华硕x88s笔记本参数详解
华硕x88s拆机教程 华硕x88s笔记本参数详解
-
 改U盘保护 详解“若没有StorageDevicePolicies项则
改U盘保护 详解“若没有StorageDevicePolicies项则
-
 摄像头安装程序安装步骤图文详解
摄像头安装程序安装步骤图文详解
-
 IE临时文件夹在哪?如何更改Internet临时文件夹位置?
IE临时文件夹在哪?如何更改Internet临时文件夹位置?
-
 快用苹果助手如何安装?安装不了究竟怎么回事
快用苹果助手如何安装?安装不了究竟怎么回事
-
 速看!金陵通介绍视频误曝光,Apple Pay 正测试支
速看!金陵通介绍视频误曝光,Apple Pay 正测试支
-
 联想旭日C430A-PX配置性能如何
联想旭日C430A-PX配置性能如何
-
 微信上线6个新表情 快更新看看
微信上线6个新表情 快更新看看
-
 2020中国软件百强榜单公布 华为蝉联第一
2020中国软件百强榜单公布 华为蝉联第一
-
 部分用户反映校园优惠套餐被叫停?联通解释:卡
部分用户反映校园优惠套餐被叫停?联通解释:卡
-
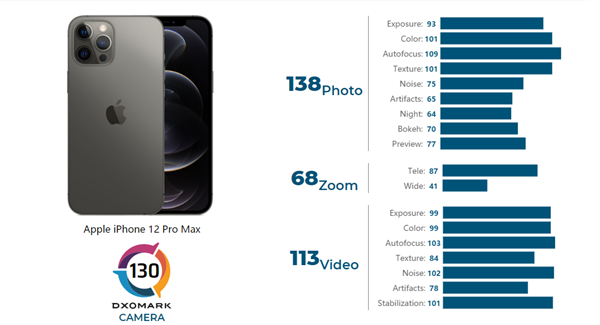 DXO公布iPhone 12 Pro Max评分:挑战Mate40 Pro输了
DXO公布iPhone 12 Pro Max评分:挑战Mate40 Pro输了
-
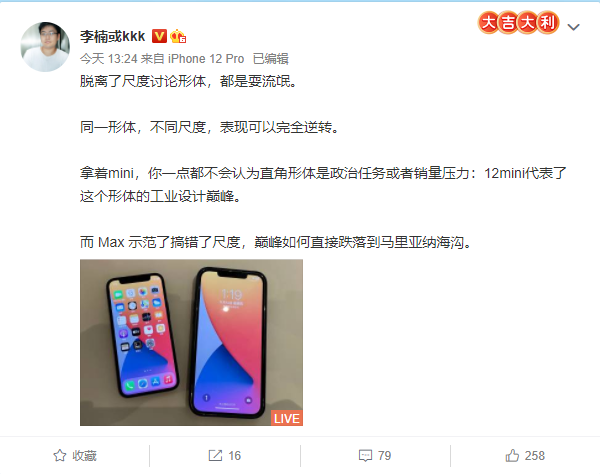 李楠表示:iPhone 12 mini是工业设计之巅 Max版垫底
李楠表示:iPhone 12 mini是工业设计之巅 Max版垫底