AI在又一个游戏中虐哭人类! 团体游戏纷纷沦陷!

“夺旗”既是一款儿童在夏令营活动上常玩的一款游戏,也是《雷神之锤3》(Quake III)和《守望先锋》(Overwatch)等热门游戏的一部分。
不管它作为儿童的夏令营游戏还是电子游戏,它都是一项团队运动。每一方都守卫着一面旗帜,同时也在计划夺取另一方的旗帜并将其带回基地。赢得比赛需要良好的传统团队合作,并且在防守和进攻之间取得协调平衡。
换句话说,“夺旗”这一游戏需要一系列看起来非常人性化的技能。但伦敦人工智能实验室的研究人员表示,至少在虚拟世界中,机器也能掌握这款游戏。
在周四发表在《科学》(Science)杂志上的一篇论文中,研究人员的报告称,他们设计了一种自动虚拟程序,当玩家在《雷神之震3》中玩“夺旗”(capture the flag)游戏模式时,该程序会表现出类似人类的行为。这些程序能够与人类玩家组队,与人类玩家并肩作战,从而相应地调整它们的行为。
与谷歌同属一家母公司的DeepMind实验室的研究员沃伊切赫·扎尔内基(Wojciech Czarnecki)说:“这些程序可以适应具有任意技能的队友。”
通过数千小时的比赛,这些虚拟程序学会了非常特殊的技能。比如当队友快要抓到一面旗子时,它们会冲向敌方的大本营。正如人类玩家所知道的,当对方的旗帜被带到自己的基地时,新的旗帜就会出现在对方的基地,等待着玩家们去夺取。
DeepMind的项目是构建人工智能的广泛努力的一部分,这种人工智能可以玩极其复杂的三维视频游戏,包括《雷神之锤3》、《Dota 2》和《星际争霸2》。许多研究人员认为,虚拟领域的成功最终将改进现实世界中的自动化系统。
例如,这些技能可以让仓库机器人受益,因为它们可以通过团队合作把货物从一个地方搬到另一个地方,或者帮助自动驾驶汽车在拥挤的交通中进行集体导航。“游戏一直是人工智能的基准,”位于旧金山的OpenAI实验室负责类似研究的格雷格·布罗克曼(Greg Brockman)说。“如果你不能用人工智能解决游戏中的难题,你就不能指望解决任何其他问题。”
就算在现在,在像《雷神之锤3》这样的游戏中建立一个能够与人类玩家相匹配的人工智能系统似乎还是不可能的。但在过去几年里,DeepMind、OpenAI和其他实验室取得了重大进展,这要归功于一种名为“强化学习”的数学技术,这种技术允许机器通过反复试验来学习任务。
通过一遍又一遍地玩游戏,一个自动化的程序可以学习哪些策略能带来成功,哪些不能。如果这个程序在队友准备夺取一面旗子时向对手的基地移动,能够不断地赢得更多的分数的话,那么该程序就会把这种战术添加到自己的算法库中。
2016年,DeepMind的研究人员使用同样的基本技术,建立了一个系统,让人工智能可以在围棋中击败世界顶级棋手。许多专家曾认为,考虑到《雷神之锤3》的巨大复杂性,让人工智能在这一游戏中击败对手这一目标要再过10年才能实现。
第一人称的自主电子游戏要复杂得多,尤其是当它们涉及到队友之间的协调时。DeepMind的程序需要通过玩大约45万回合才能学会如何夺取这面旗帜,他们在数周的训练中积累了大约人类四年的游戏经验。起初,程序们惨败。但他们逐渐学会了游戏的微妙之处,比如当队友突袭对手的大本营时,它们知道该如何辅助队友。

自从完成这个项目后,DeepMind的研究人员还设计了另外一个系统,可以打败一款以太空为背景的战略游戏《星际争霸2》(StarCraft II)中的专业玩家。在OpenAI,研究人员建立了一个系统,可以控制《Dota2》,这款游戏就像“夺旗”的升级版。今年4月,一支由5个虚拟的人工智能程序组成的队伍击败了一支由5名世界上最优秀的人类玩家组成的队伍。
去年,有“闪电战”之称的职业Dota 2玩家兼评论员威廉·李(William Lee)与一种早期版本的人工智能打了一场比赛,这一人工智能程序只能进行一对一的比赛,打不了团队比赛,因此威廉·李对此并不感兴趣。但随着这些程序的深入学习,威廉·李开始慢慢地被这些虚拟的程序所震撼到了。
“我认为这台机器不可能打出五人团体战,更不用说赢了,”他说。“但是我完全惊呆了。”
尽管这类技术让许多游戏玩家感到惊讶与佩服,但许多人工智能专家质疑它最终能否解决现实问题。专门研究人工智能的佐治亚理工学院(Georgia Tech College of Computing)教授马克·里德尔(Mark Riedl)说,DeepMind的虚拟程序实际上并没有团队中的合作,它们只是对游戏中发生的事情做出反应,而不是像人类玩家那样彼此交换信息。(即使只是蚂蚁也可以通过交换化学信号来合作。)
虽然结果看起来像是团队合作,但这些程序之所以能够实现这一点,是因为它们能够独立地完全理解游戏中所发生的一切。
“如何定义团队合作不是我想解决的问题,”DeepMind的另一位研究人员马克斯·加德伯格(Max Jaderberg)说。“但只有在依靠队友的情况下,才有可能有一位虚拟“玩家”出现在对手的大本营里,伺机夺取旗帜”
这样的游戏并不像现实世界那么复杂。“三维环境的设计是为了让导航变得容易,”里德博士说。“《雷神之锤》的策略和协调很简单。”
强化学习非常适合这种游戏。在电子游戏中,程序能够很容易就确定成功的衡量标准——更多的分数。(在“夺旗这一游戏”中,玩家根据夺旗数量获得点数。)但在现实世界中,没有人记分。研究人员必须用其他方式来定义成功。

这是可以做到的,至少在简单的任务上是没问题的。在OpenAI,研究人员已经训练了一只机械手,可以像孩子一样摆弄字母块。如果你告诉这只机械手展示字母A,它就会拿起字母A的方块。
在谷歌机器人实验室,研究人员已经证明,机器人可以学会捡起随机的物品,比如乒乓球和塑料香蕉,然后把它们扔到几英尺外的垃圾箱里。这种技术可以帮助亚马逊(Amazon)、联邦快递(FedEx)等公司运营的大型仓库和配送中心对物品进行分类。如今这些任务仍然是由人工处理的。
当像DeepMind和OpenAI这样的实验室处理更大的问题时,他们可能开始需要非常大的计算能力。OpenAI的系统在几个月的时间里(超过4.5万年的游戏时间)学会了玩《dota2》,但是它开始依赖于成千上万的电脑芯片。布罗克曼说,仅仅租用所有这些芯片的使用权就花费了实验室数百万美元。
DeepMind和OpenAI能够负担得起所有这些计算能力所带来的资金压力。OpenAI的资金来自硅谷的各种巨头,包括科斯拉风投(Khosla Ventures)和科技业亿万富翁里德·霍夫曼(Reid Hoffman)。但卡耐基·梅隆大学(Carnegie Mellon University)的人工智能研究员戴文德拉·查普劳德(Devendra Chaplot)说,学术实验室和其他小型机构做不到这一点。对一些人来说,他们担心一些资金充足的实验室将主导人工智能的未来。
但是,即使是大型实验室也可能没有足够的计算能力将这些技术应用到复杂的现实世界中,这可能需要更强大的人工智能形式,它们可以更快地学习。尽管这些人工智能程序现在可以在虚拟世界中赢得胜利,但它们在夏令营的空地上(现实世界)想要战胜人类还是毫无希望的——而且在相当长一段时间内都将是如此。
(选自:NYTimes原作者:Cade Metz)
相关推荐
-
AI端的未来在哪?
-
马斯克:要创造一个有益于人民的AI
-
这些AI技术正被应用于临床 辅助医疗新变革
-
 AI语音真假面:实时变声 一秒复制或模仿你讲话
AI语音真假面:实时变声 一秒复制或模仿你讲话
-
真假“比尔·盖茨”难辨 AI精确复制声音
-
AI让虚拟触觉”技术 ,提升人的触觉感知 电子皮肤
-
AI语音技术发展要向善行善
-
“科技素养提升计划”惠及1000所农村小学 AI公益助
-
AI触觉手套神奇在哪里?
-
寒武纪正式宣布推出云端AI芯片中文品牌“思元”
-
 天猫催发货、改地址只要说句话,就有AI机器人为你“
天猫催发货、改地址只要说句话,就有AI机器人为你“
-
这个团队做到了用AI“狙杀”威胁地球的天体! 那需
-
搜狗与北京互联网法院联合外发布首个“AI虚拟法官”
-
 “百度AI寻人”救助寻亲工作跨入AI时代 两年实现64
“百度AI寻人”救助寻亲工作跨入AI时代 两年实现64
-
AI到底会不会取代同传? 真人和AI同场竞技,AI还是
-
判案小能手:“AI+政法”黑科技可0.1秒锁定嫌疑人
-
AI从走路姿势就能分辨你的情绪!
-
AI音乐家“出道”了!你期待吗?
-
你的AI护士小姐姐已上线 可减轻人类护士30%工作量
-
AI正在走向一个异构的世界
-
 Android 12“App Pairs”功能:允许用户并排使用两个应用
Android 12“App Pairs”功能:允许用户并排使用两个应用
-
 NASA新火箭关键测试不幸失败 美登月计划或被迫推迟?
NASA新火箭关键测试不幸失败 美登月计划或被迫推迟?
-
 迅雷高速通道破解方法 迅雷高速通道如何破解
迅雷高速通道破解方法 迅雷高速通道如何破解
-
 ubuntu手机操作系统 手机版Ubuntu将给哪些人带来好处?
ubuntu手机操作系统 手机版Ubuntu将给哪些人带来好处?
-
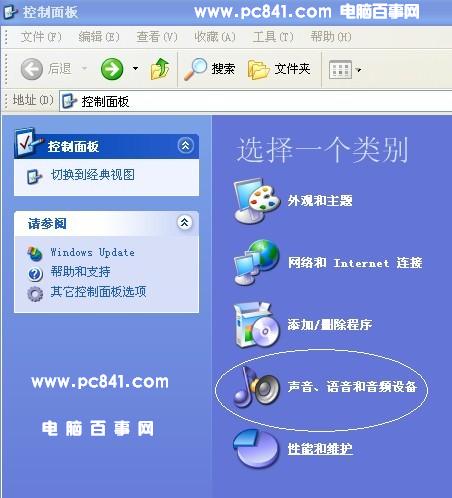 电脑开关机音乐下载 电脑开关机音乐设置教程
电脑开关机音乐下载 电脑开关机音乐设置教程
-
 去年12月中国手游发行商全球收入排名:腾讯第一
去年12月中国手游发行商全球收入排名:腾讯第一
-
 长城汽车申请新商标曝光啦!
长城汽车申请新商标曝光啦!
-
 网友晒“哈哈哈”频率 有的人居然一年哈了8.6万次
网友晒“哈哈哈”频率 有的人居然一年哈了8.6万次
-
 华硕x88s拆机教程 华硕x88s笔记本参数详解
华硕x88s拆机教程 华硕x88s笔记本参数详解
-
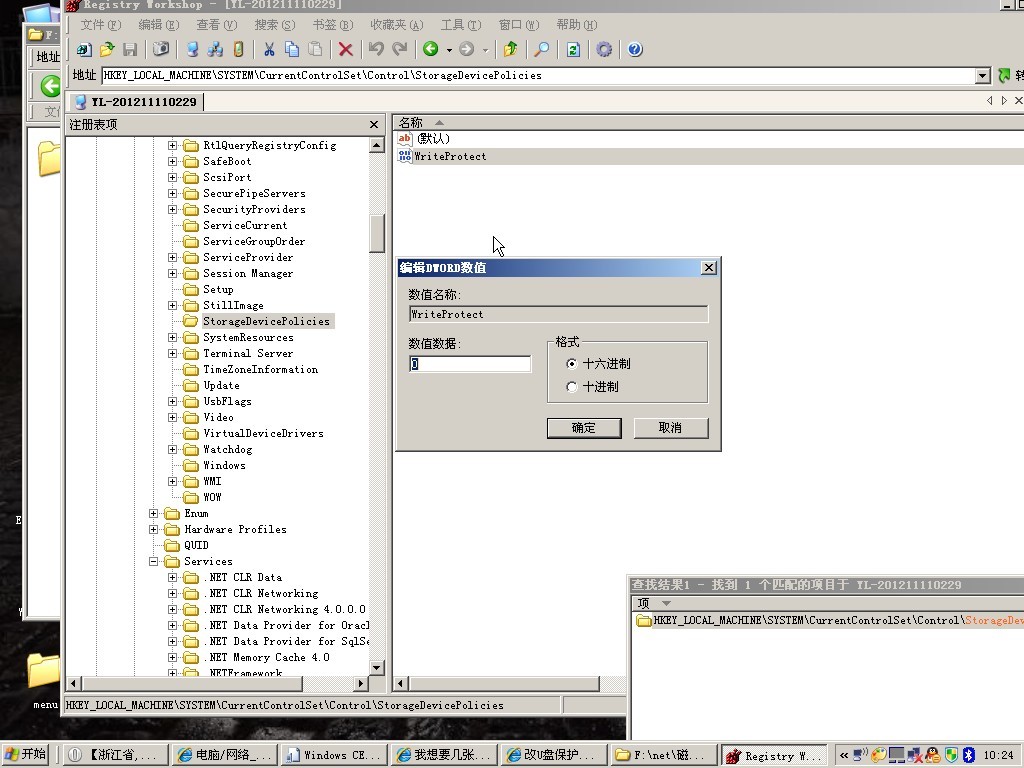 改U盘保护 详解“若没有StorageDevicePolicies项则
改U盘保护 详解“若没有StorageDevicePolicies项则
-
 摄像头安装程序安装步骤图文详解
摄像头安装程序安装步骤图文详解
-
 IE临时文件夹在哪?如何更改Internet临时文件夹位置?
IE临时文件夹在哪?如何更改Internet临时文件夹位置?
-
 快用苹果助手如何安装?安装不了究竟怎么回事
快用苹果助手如何安装?安装不了究竟怎么回事
-
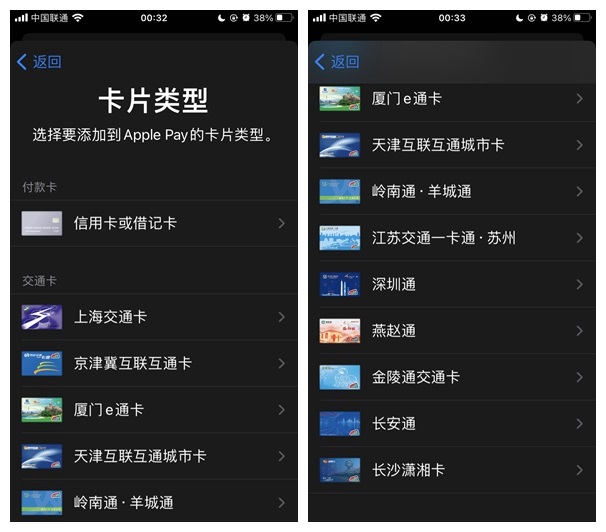 速看!金陵通介绍视频误曝光,Apple Pay 正测试支
速看!金陵通介绍视频误曝光,Apple Pay 正测试支
-
 联想旭日C430A-PX配置性能如何
联想旭日C430A-PX配置性能如何
-
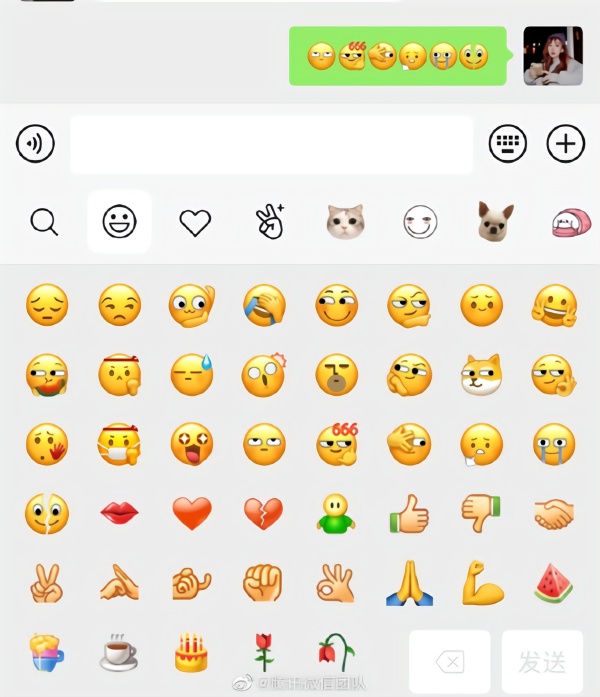 微信上线6个新表情 快更新看看
微信上线6个新表情 快更新看看
-
 2020中国软件百强榜单公布 华为蝉联第一
2020中国软件百强榜单公布 华为蝉联第一
-
 部分用户反映校园优惠套餐被叫停?联通解释:卡
部分用户反映校园优惠套餐被叫停?联通解释:卡
-
 DXO公布iPhone 12 Pro Max评分:挑战Mate40 Pro输了
DXO公布iPhone 12 Pro Max评分:挑战Mate40 Pro输了
-
 李楠表示:iPhone 12 mini是工业设计之巅 Max版垫底
李楠表示:iPhone 12 mini是工业设计之巅 Max版垫底