对抗性数据和黑暗人工智能的潜在后果

近年来,人工智能已经取得了长足的进步,但正如许多人工智能使用者所表明的那样,人工智能仍然容易出现一些人类并不会犯的惊人错误。虽然这些错误有时可能是人工智能进行学习时不可避免的后果,但越来越明显的是,一个比我们意想中严重得多的问题正带来越来越大的风险:对抗性数据。
对抗性数据描述了这样一种情况,人类用户故意向算法提供已损坏的信息,损坏的数据打乱了机器学习过程,从而欺骗算法得出虚假的结论或不正确的预测。
作为一名生物医学工程师,笔者认为对抗数据是一个值得关注的重要话题。最近,加州大学伯克利分校(UC Berkeley)教授唐恩·宋(Dawn Song)“欺骗”了一辆自动驾驶汽车,让它以为停车标志上的限速是每小时45英里。
这种性质的恶意攻击很容易导致致命的事故。同样地,受损的算法数据可能导致错误的生物医学研究,重则危及生命或影响医学事业的创新发展。
直到最近,人们才意识到对抗性数据的威胁,我们不能再忽视它了。
对抗性数据是如何产生的呢?
有趣的是,即使不带任何恶意,也可能产生对抗性数据的输出。这在很大程度上是因为算法能够“观察”到我们人类无法识别的数据中的东西。由于这种可见性,麻省理工学院最近的一个案例研究将对抗性描述为一种特性,而不是故障。
在这项研究中,研究人员将人工智能学习过程中的“鲁棒性”和“非鲁棒性”特征进行了分离。鲁棒特征通常可以被人类感知到,而非鲁棒特征只能被人工智能检测到。研究人员尝试用一种算法让人工智能识别猫的图片,结果显示,系统通过观察图像中的真实模式,却得出错误的结论。
错误识别发生的原因是,人工智能看到的是一组无法明显感知的像素,使得它无法正确识别照片。这导致在识别算法的过程中,系统在无意中被训练成使用误导模式。
这些非鲁棒性特征作为一种“干扰噪声”,导致算法的结果存在缺陷。因此,黑客要想干扰人工智能,往往只需要引入一些非鲁棒特性,这些特性不容易被人眼识别,但可以明显地改变人工智能的输出结果。
对抗性数据和黑暗人工智能的潜在后果
正如安全情报局的穆阿扎姆·汗所指出的,依赖于对抗性数据的攻击主要有两种类型:“中毒攻击”和“闪躲攻击”。在中毒攻击中,攻击者提供了一些输入示例,这些输入示例使得决策边界转移向对攻击者有利的方向;在闪躲攻击中,攻击者会使得程序模型对样本进行错误分类。
例如,在笔者所熟悉的生物医学环境中,对抗性数据的攻击可能会导致算法错误地将有害或受污染的样本标记为良性且清洁,这就可能导致错误的研究结果或不正确的医疗诊断。
让人工智能学习算法也可以被用来驱动专门为帮助黑客而设计的恶意人工智能程序。正如《恶意人工智能报告》所指出的,黑客可以利用人工智能为他们的各项破坏活动提供便利,从而实现更广泛的网络攻击。
尤其,机器学习能够绕过不安全的物联网设备,让黑客更容易窃取机密数据、违法操纵公司数据库等等。本质上,一个黑暗的人工智能工具可以通过对抗性数据来“感染”或操纵其他人工智能程序。中小型企业往往面临更高的风险,因为他们没有先进的网络安全指标。
保护措施
尽管存在这些问题,对抗性数据也可以被用于积极的方面。事实上,许多开发人员已经开始使用对抗性数据来检测自己的系统漏洞,从而使他们能够在黑客利用漏洞之前实现安全升级。其他开发人员正在使用机器学习来创建另一种人工智能系统,确保其能更擅长识别和消除潜在的数据威胁。
正如乔·代沙尔特在一篇发表于“基因工程及生物技术新闻”的文章中所解释的那样,许多这些人工智能工具已经能够在计算机网络上寻找可疑的活动,分析时间通常为几毫秒,并能够在其造成任何损害之前消除祸端,这些罪魁祸首通常来自流氓文件或程序。
他补充说,这种方法与传统的信息技术安全不同,传统的信息技术安全更关注于识别已知威胁的特定文件和程序,而不是研究这些文件和程序的行为。
当然,机器学习算法本身的改进也可以减少对抗性数据带来的一些风险。然而,最重要的是,这些系统并不是完全独立的。人工输入和人工监督仍然是识别鲁棒特征和非鲁棒特征之间差异的关键,以确保错误的识别不会导致错误的结果。利用真实相关性的额外训练可以进一步降低人工智能的易受攻击特性。
显然,在不久的将来,对抗性数据将继续对人类世界构成挑战。但在这样一个时代,人工智能可以被用来帮助我们更好地理解人类大脑、解决各种世界问题。我们不能低估这种数据驱动威胁的紧迫性。处理对抗性数据并采取措施对抗黑暗人工智能应该成为科技界的首要任务之一。
(选自:The Next Web原作者:Jordan French编译:网易智能 参与:Yuki)
相关推荐
-
 数据匿名化尚不足以很好地保护个人隐私
数据匿名化尚不足以很好地保护个人隐私
-
 云南首个“云茶大数据中心”启动发布会8日在昆明举
云南首个“云茶大数据中心”启动发布会8日在昆明举
-
总投资20亿元 上汽集团云计算数据中心在郑州落户
-
大数据、云计算等因“无人”场景获得了爆发式成长
-
用大数据为顾客“画像” 助力小企业互联网转型
-
“90后”数据标注师:我们就像AI的“幼儿教师”
-
大数据创新创业风头正劲 专家建言献策
-
大数据杀熟消费者维权难 算法应用不公该怎样规制
-
 Android 12“App Pairs”功能:允许用户并排使用两个应用
Android 12“App Pairs”功能:允许用户并排使用两个应用
-
 NASA新火箭关键测试不幸失败 美登月计划或被迫推迟?
NASA新火箭关键测试不幸失败 美登月计划或被迫推迟?
-
 迅雷高速通道破解方法 迅雷高速通道如何破解
迅雷高速通道破解方法 迅雷高速通道如何破解
-
 ubuntu手机操作系统 手机版Ubuntu将给哪些人带来好处?
ubuntu手机操作系统 手机版Ubuntu将给哪些人带来好处?
-
 电脑开关机音乐下载 电脑开关机音乐设置教程
电脑开关机音乐下载 电脑开关机音乐设置教程
-
 去年12月中国手游发行商全球收入排名:腾讯第一
去年12月中国手游发行商全球收入排名:腾讯第一
-
 长城汽车申请新商标曝光啦!
长城汽车申请新商标曝光啦!
-
 网友晒“哈哈哈”频率 有的人居然一年哈了8.6万次
网友晒“哈哈哈”频率 有的人居然一年哈了8.6万次
-
 华硕x88s拆机教程 华硕x88s笔记本参数详解
华硕x88s拆机教程 华硕x88s笔记本参数详解
-
 改U盘保护 详解“若没有StorageDevicePolicies项则
改U盘保护 详解“若没有StorageDevicePolicies项则
-
 摄像头安装程序安装步骤图文详解
摄像头安装程序安装步骤图文详解
-
 IE临时文件夹在哪?如何更改Internet临时文件夹位置?
IE临时文件夹在哪?如何更改Internet临时文件夹位置?
-
 快用苹果助手如何安装?安装不了究竟怎么回事
快用苹果助手如何安装?安装不了究竟怎么回事
-
 速看!金陵通介绍视频误曝光,Apple Pay 正测试支
速看!金陵通介绍视频误曝光,Apple Pay 正测试支
-
 联想旭日C430A-PX配置性能如何
联想旭日C430A-PX配置性能如何
-
 微信上线6个新表情 快更新看看
微信上线6个新表情 快更新看看
-
 2020中国软件百强榜单公布 华为蝉联第一
2020中国软件百强榜单公布 华为蝉联第一
-
 部分用户反映校园优惠套餐被叫停?联通解释:卡
部分用户反映校园优惠套餐被叫停?联通解释:卡
-
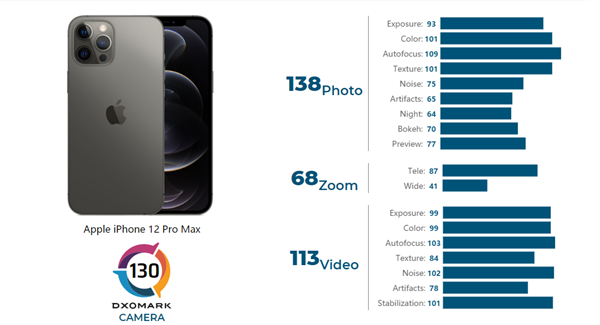 DXO公布iPhone 12 Pro Max评分:挑战Mate40 Pro输了
DXO公布iPhone 12 Pro Max评分:挑战Mate40 Pro输了
-
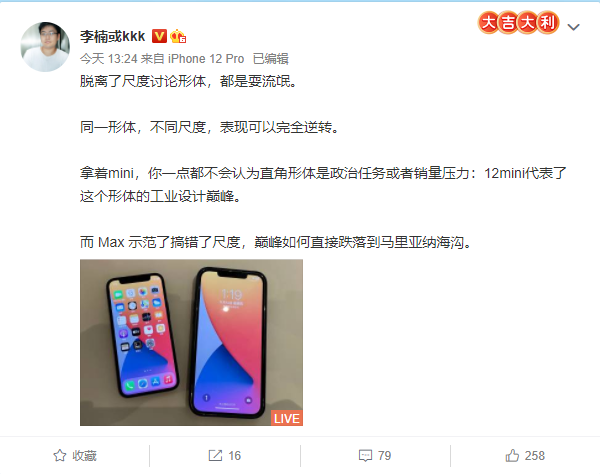 李楠表示:iPhone 12 mini是工业设计之巅 Max版垫底
李楠表示:iPhone 12 mini是工业设计之巅 Max版垫底