探境科技发布首个离在线一体语音识别解决方案,即Voitist音旋风612
2月底,探境科技发布了由低功耗系列、主打系列、旗舰系列组成的三大系列、6颗AI芯片组成的产品矩阵。其中,探境发布了具备AI双麦降噪功能的语音识别方案,即Voitist音旋风612,这也是首个离在线一体的语音识别解决方案。
AI降噪+HONN 无惧家居噪音
信噪比,是衡量需要识别的目标声源与其它干扰声源强度比值的对数。一般将信噪比低于15dB的称为噪声环境。信噪比越低,识别难度越大。
在语音识别的研发过程中,一个完整的识别链路可以简化为麦克风输入、降噪处理、语音识别、识别结果输入四个环节。想做好识别,首先要在降噪处理上下功夫。
据探境科技副总裁李同治介绍,为了验证探境AI降噪算法的有效性,他曾将一批信噪比在3dB左右的语音数据送到一个知名的云端公开语音识别引擎做了测试,降噪后比降噪前提高30%识别准确率。
在传统的语音识别算法里,用的最多的是全连接的操作,叫DNN/DTNN。相比较于全连接操作,卷积操作能够提供更高的计算强度,且卷积运算与人类大脑负责感知模块的处理方法类似,能够提取满足大脑认知的本质特征。
探境将其计算机视觉中的一些经验迁移到语音识别中,在语音识别算法上加入了更多的卷积操作,重新设计了一个高计算强度的神经网络,即HONN(High Operation Neural Network)。
正是依托于AI降噪技术+HONN神经网络,探境的Voitist音旋风611,可以覆盖绝大部分的生活场景,无惧各种噪音干扰。
端到端双麦加持 攻克0dB环境
为了提升低这些场景下的识别率,还需要使用麦克风阵列来增强语音信号。探境在双麦算法上有自己的独门绝技—FCSP双麦识别算法。”
“为了克服传统分模块语音增强算法的这些缺点,我们设计出了基于FCSP的端到端AI双麦算法。”李同治对记者表示。FCSP(Frequency Complex Subspace Projection)是探境自研的频域复数子空间投影算法的简称。
这个算法直接输入阵列信号,输出的是最终的识别结果,中间部分全部交给基于深度学习的AI算法来处理,不再使用传统的数字信号处理方法。信号增强与识别模块整体以降低识别错误率为目标进行优化,避免了语音增强与语音识别模块错配的问题。

“端到端”是目前国际上最前沿的处理算法。通过AI语音算法+HONN神经网络模型来提升识别率,再通过FCSP“端到端”的双麦处理算法简化识别流程,降低最终识别错误率,探境的语音算法实现了跨越式的升级。
探境自研的SFA架构,以存储驱动计算,具有能效比高、资源利用率高、通用性强等特点。在SFA架构上实现深度学习时,只需要一个较高层次的神经网络描述。SFA的编译器首先将这个神经网络进行全部融合,然后根据具体架构实现的规模产生一个统一的存储流图,再进行存储节点的时空映射,最后根据各个节点之间的计算类型配置计算单元,组合起来形成一个统一的固件供SFA控制器使用。
在28nm常规工艺芯片的对比测试中,SFA架构在乘法器数目相同情况下,结果如下表。(DRAM为LPDDR4)。
这意味着SFA架构所采用的各种微观和宏观调度算法,比较“类CPU架构”采用的基于总线和指令集的映射方法,在近似存储量、近似算力、近似外部存储带宽、近似功耗约束的前提下,可以获得8~12倍的利用率收益。
“SFA(存储优先)架构是探境的产品基石,正是借助SFA的优势,我们的AI芯片产品才能‘裂变式’的推出,大大加快了探境的商业化落地速度。”探境CEO鲁勇这样评价SFA架构的意义。

“探境不仅仅是一个语音芯片公司,而是一家语音、图像整体结合的AI芯片公司。AI芯片这一领域不像手机APP那样,瞬间可以凭一款应用获得数百万的用户,AI芯片更像马拉松长跑,比的是耐力,而不是冲刺速度,在这场比赛中,不是要看谁跑得快,而是要看谁有潜力到达终点,谁在中途不走岔路。”鲁勇向记者表示。
相关推荐
-
 Android 12“App Pairs”功能:允许用户并排使用两个应用
Android 12“App Pairs”功能:允许用户并排使用两个应用
-
 NASA新火箭关键测试不幸失败 美登月计划或被迫推迟?
NASA新火箭关键测试不幸失败 美登月计划或被迫推迟?
-
 迅雷高速通道破解方法 迅雷高速通道如何破解
迅雷高速通道破解方法 迅雷高速通道如何破解
-
 ubuntu手机操作系统 手机版Ubuntu将给哪些人带来好处?
ubuntu手机操作系统 手机版Ubuntu将给哪些人带来好处?
-
 电脑开关机音乐下载 电脑开关机音乐设置教程
电脑开关机音乐下载 电脑开关机音乐设置教程
-
 去年12月中国手游发行商全球收入排名:腾讯第一
去年12月中国手游发行商全球收入排名:腾讯第一
-
 长城汽车申请新商标曝光啦!
长城汽车申请新商标曝光啦!
-
 网友晒“哈哈哈”频率 有的人居然一年哈了8.6万次
网友晒“哈哈哈”频率 有的人居然一年哈了8.6万次
-
 华硕x88s拆机教程 华硕x88s笔记本参数详解
华硕x88s拆机教程 华硕x88s笔记本参数详解
-
 改U盘保护 详解“若没有StorageDevicePolicies项则
改U盘保护 详解“若没有StorageDevicePolicies项则
-
 摄像头安装程序安装步骤图文详解
摄像头安装程序安装步骤图文详解
-
 IE临时文件夹在哪?如何更改Internet临时文件夹位置?
IE临时文件夹在哪?如何更改Internet临时文件夹位置?
-
 快用苹果助手如何安装?安装不了究竟怎么回事
快用苹果助手如何安装?安装不了究竟怎么回事
-
 速看!金陵通介绍视频误曝光,Apple Pay 正测试支
速看!金陵通介绍视频误曝光,Apple Pay 正测试支
-
 联想旭日C430A-PX配置性能如何
联想旭日C430A-PX配置性能如何
-
 微信上线6个新表情 快更新看看
微信上线6个新表情 快更新看看
-
 2020中国软件百强榜单公布 华为蝉联第一
2020中国软件百强榜单公布 华为蝉联第一
-
 部分用户反映校园优惠套餐被叫停?联通解释:卡
部分用户反映校园优惠套餐被叫停?联通解释:卡
-
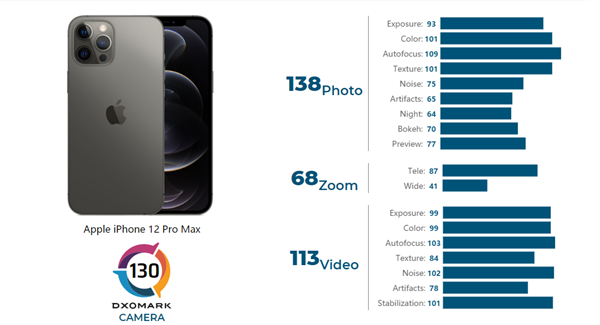 DXO公布iPhone 12 Pro Max评分:挑战Mate40 Pro输了
DXO公布iPhone 12 Pro Max评分:挑战Mate40 Pro输了
-
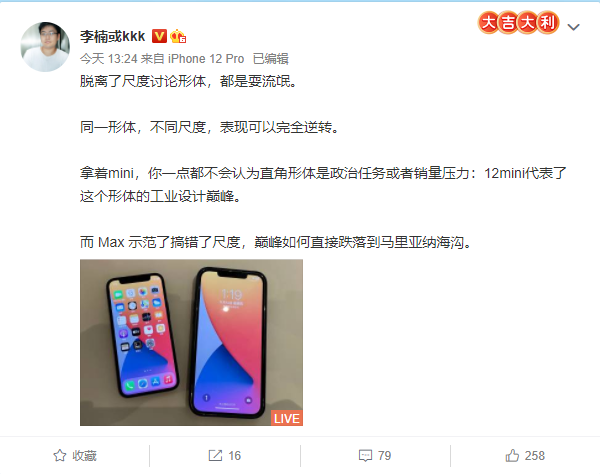 李楠表示:iPhone 12 mini是工业设计之巅 Max版垫底
李楠表示:iPhone 12 mini是工业设计之巅 Max版垫底